출처 http://www.popit.kr/bm25-elasticsearch-5-0%EC%97%90%EC%84%9C-%EA%B2%80%EC%83%89%ED%95%98%EB%8A%94-%EC%83%88%EB%A1%9C%EC%9A%B4-%EB%B0%A9%EB%B2%95/
색 점수
검색이란 사용자가 입력한 검색 쿼리(query)에 대해 관련있는 문서를 매칭한 후, 관련성에 따라 정렬하는 과정이다. 관련성(relevance)은 주어진 쿼리와 매칭되는 문서를 관련된 정도에 따라 수치화 한 값으로, 검색 점수(score)라고 부른다. 또한 쿼리는 “최순실“, “통일교“와 같이 한단어 일수도 있지만, “최순실 게이트“과 같이 여러 단어일수도 있다. 이 경우 “최순실”, “게이트”에 대한 각 단어의 검색 점수를 합해야 하며, 이러한 각 단어를 텀(term)이라고 부른다.

그림. 쿼리에 대한 문서의 검색 점수 계산
우리가 익히 알고 있는 TF/IDF 알고리즘은 이러한 검색 점수를 계산하기 위한 가장 일반적인 방법이다.
TF/IDF
루씬의 TF/IDF 알고리즘은 아래와 같다.
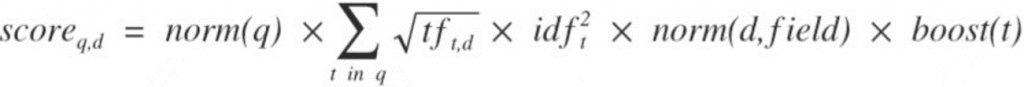
그림. 루씬 TF/IDF 수식(출처: Real-time Analytics & Anomaly detection using Hadoop, Elasticsearch and Storm)
수식은 복잡하지만 그 의미는 직관적이다.
TF(Term Frequency): 단어 빈도
텀(term)이 문서에 등장하는 횟수로, 많이 등장할수록 문서의 검색 점수는 당연히 높아진다.
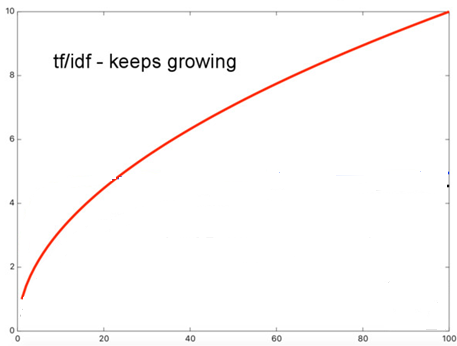
그림. TF가 높아질수록 점수가 높아진다(출처: Elasticsearch, Improved Text Scoring with BM25)
IDF(Inverse Document Frequency): 문서 역빈도
문서 빈도(DF: Document Frequency)는 텀(term)이 등장하는 문서 개수로, 여러 문서에 등장할수록 문서의 검색 점수가 낮아진다. IDF는 1/DF다.
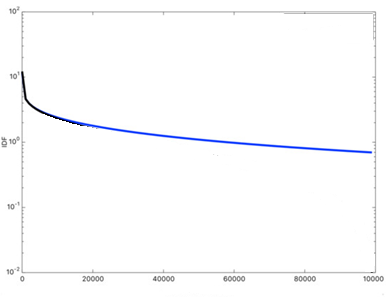
그림. DF가 높아질수록 점수가 낮아진다(출처: Elasticsearch, Improved Text Scoring with BM25)
“the”, “a”, “is”와 같이 문장에서 거의 항상 등장하는 텀(term)은 검색 결과에 영향을 미치지 않게 하기 위한 것으로, 이러한 단어들은 불용어(stop word)라고 부른다.
norm: 문서 길이 가중치
텀(term)이 등장하는 문서의 길이에 대한 가중치로, 문서 길이가 길수록 검색 점수가 낮아진다.
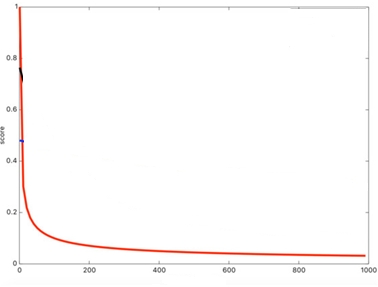
그림. 문서 길이가 길수록 점수가 낮아진다(출처: Elasticsearch, Improved Text Scoring with BM25)
“철수의 취미는 축구다”와 “영희의 취미는 축구와 야구다”와 같은 문장이 있을 때 “축구”로 검색한 경우, “철수의 취미는 축구다”라는 문서의 검색 점수가 더 높다. 직관적으로 보더라도, 여가생활에 철수는 “축구”만 하고, 영희는 “축구”와 “야구”를 섞어서 할 것이므로, 철수는 영희보다 “축구”를 더 좋아할 가능성이 높을 것이다.
나머지들
수식의 첫번째 항목인 쿼리 norm과 마지막 항목인 텀 부스트(boost)는 이 글에서는 크게 신경쓰지 않아도 된다.
BM25
BM25를의 검색 점수를 계산하는 수식은 다음과 같다.
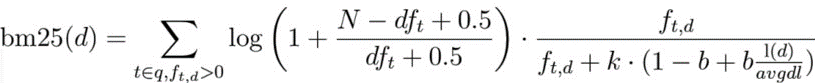
그림. BM25 수식(출처: Elasticsearch, Improved Text Scoring with BM25)
수식을 수학적으로 이해하는 것도 중요하겠지만, TF/IDF와 비교하여 검색 결과에 어떤 영향을 주는지를 느낄 수만 있다면 충분하다.
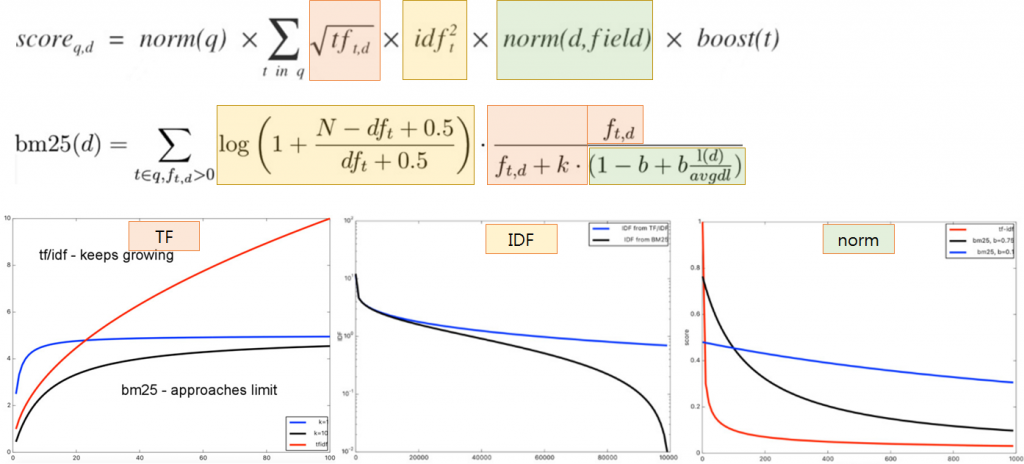
그림. 항목별 TF/IDF와 BM25 비교(출처: Elasticsearch, Improved Text Scoring with BM25)
TF(Term Frequency): 단어 빈도
TF의 영향이 줄어든다.
TF에서는 단어 빈도가 높아질수록 검색 점수도 지속적으로 높아지는 반면, BM25에서는 특정 값으로 수렴한다.
IDF(Inverse Document Frequency): 문서 역빈도
IDF의 영향이 커진다.
BM25에서는 DF가 높아지면 검색 점수가 0으로 급격히 수렴하므로, 불용어가 검색 점수에 영향을 덜 미친다.
norm: 문서 길이 가중치
문서 길이의 영향이 줄어든다.
BM25에서는 문서의 평균 길이(avgdl)를 계산에 사용하며, 문서의 길이가 검색 점수에 영향을 덜 미친다.
추가로
Coordination Factor
루씬 TF/IDF 알고리즘에는 coordination 항목도 검색 점수에 영향을 미친다. coordination 요소란 쿼리에 포함된 텀(term)을 더 많이 가진 문서에 대해 더 많은 점수 가중치를 부여하는 요소다.

그림. “holiday, china”로 검색한 경우 두 문서의 검색 점수(출처: Elasticsearch, Improved Text Scoring with BM25)
예를 들어 “holiday, china”로 검색한 경우, 첫 번째 문서는 “holiday”와 “china” 단어를 모두 가지며 최종 점수는 9점이다. 반면 두 번째 문서는 “china” 단어만 등장하며, 최종 점수는 15점이다. 단순히 TF로만 계산한다면, 두 번째 문서가 더 검색점수가 높지만, 실제로 관련성이 더 높은 문서는 첫 번째 문서다. coordination 항목은 이러한 불린(boolean) 쿼리에서 쿼리에 포함된 여러 텀(term)이 문서에 동시에 나타나는 경우 더 높은 가중치를 부여한다. 자세한 내용은 The Definitive Guide [2.x] > Lucene’s Practical Scoring Function에서 찾아볼 수 있다.
BM25 알고리즘에서 coordination 항목이 없으며, 활성화할 필요가 없다.
BM25 알고리즘 사용하기
5.0.0 이전 버전에서 기본 검색 알고리즘인 TF/IDF 대신 BM25를 사용하려면, 전역으로 설정하거나 각 필드별로 설정할 수 있다. 전역 설정은 elasticsearch.yml 파일의 index.similarity.default.type 항목을 BM25로 설정한다.









